20 分钟
scala akka actor一种并发模型(二)
一、Getting Started Guide
5、示例介绍
第5部分:查询设备组
我们目前看到的对话模式很简单,就是要求Actor保持很少或者没有状态。因为:
- 设备参与者返回一个读数,这不需要改变状态
- 记录温度,只更新单个字段
- 设备组actor通过简单地添加或删除Map中的条目来维护组成员
处理查询时所有可能的情况
因为所有设备actor可能被关闭,因此有以下四种状态
- 它有一个可用的温度
Temperature(value) - 它已经回应,但没有温度可用:
TemperatureNotAvailable - 它在回答之前已经停止:
DeviceNotAvailable - 超时而没有回应:
DeviceTimedOut
将以下消息添加到DeviceGroup
//请求查询所有温度
final case class RequestAllTemperatures(requestId: Long)
//返回温度
final case class RespondAllTemperatures(requestId: Long, temperatures: Map[String, TemperatureReading])
//设备所有可能的情况
sealed trait TemperatureReading
//可读的
final case class Temperature(value: Double) extends TemperatureReading
//不可读
case object TemperatureNotAvailable extends TemperatureReading
//设备已关闭
case object DeviceNotAvailable extends TemperatureReading
//超时
case object DeviceTimedOut extends TemperatureReading实现设备组查询
设计要求
- 查询一组设备
- 提供一个超时时间、超过超时时间自动关闭(不论是否全部完成)
- 返回一组设备的温度状态(共四种情况,见上面描述)
添加DeviceGroupQuery到com.lightbend.akka.sample
package com.lightbend.akka.sample
import akka.actor.{Actor, ActorLogging, ActorRef, Cancellable, Props, Terminated}
import scala.concurrent.duration.FiniteDuration
//设备组查询actor伴生对象
object DeviceGroupQuery {
//超时
case object CollectionTimeout
def props(
actorToDeviceId: Map[ActorRef, String],
requestId: Long,
requester: ActorRef,
timeout: FiniteDuration): Props = {
Props(new DeviceGroupQuery(actorToDeviceId, requestId, requester, timeout))
}
}
class DeviceGroupQuery(
actorToDeviceId: Map[ActorRef, String], //设备actor容器
requestId: Long, //请求号
requester: ActorRef, //请求者
timeout: FiniteDuration) extends Actor with ActorLogging {//超时时间
import DeviceGroupQuery._
import context.dispatcher
//设置查询超时,查过这时间,receive将收到一个CollectionTimeout
val queryTimeoutTimer: Cancellable = context.system.scheduler.scheduleOnce(timeout, self, CollectionTimeout)
override def preStart(): Unit = {
//观察所有设备actor的变化
actorToDeviceId.keysIterator.foreach { deviceActor =>
context.watch(deviceActor)
deviceActor ! Device.ReadTemperature(0) //发送读取温度的消息
}
}
override def postStop(): Unit = {
queryTimeoutTimer.cancel()
}
override def receive: Receive =
waitingForReplies(
Map.empty,
actorToDeviceId.keySet)
//返回一个偏函数
def waitingForReplies( //到目前为止已经回复的设备
repliesSoFar: Map[String, DeviceGroup.TemperatureReading],
stillWaiting: Set[ActorRef]): Receive = { //仍然在等待的设备
case Device.RespondTemperature(0, valueOption) => //收到返回的温度
val deviceActor = sender()
val reading = valueOption match { //对温度进行封装
//设备状态:温度有值
case Some(value) => DeviceGroup.Temperature(value)
//设备状态:没有值
case None => DeviceGroup.TemperatureNotAvailable
}
//处理
receivedResponse(deviceActor, reading, stillWaiting, repliesSoFar)
case Terminated(deviceActor) => //设备已经关闭
//设备状态:设备不可访问
receivedResponse(deviceActor, DeviceGroup.DeviceNotAvailable, stillWaiting, repliesSoFar)
//设备查询超时
case CollectionTimeout =>
val timedOutReplies = //将所有超时(仍在等待的)设备的,设备状态:设置为超时
stillWaiting.map { deviceActor =>
val deviceId = actorToDeviceId(deviceActor)
deviceId -> DeviceGroup.DeviceTimedOut
}
//返回所有查询的消息
requester ! DeviceGroup.RespondAllTemperatures(requestId, repliesSoFar ++ timedOutReplies)
context.stop(self) //此时停止查询actor
}
def receivedResponse(
deviceActor: ActorRef, //当前响应的设备
reading: DeviceGroup.TemperatureReading, //当前设备温度状态
stillWaiting: Set[ActorRef], //仍然在等待的设备组(包括当前响应的设备)
//到目前为止已经相应完成的设备
repliesSoFar: Map[String, DeviceGroup.TemperatureReading]): Unit = {
context.unwatch(deviceActor) //取消观察已经响应的设备
val deviceId = actorToDeviceId(deviceActor) //获取相应响应设备的actor引用
val newStillWaiting = stillWaiting - deviceActor //将设备从等待区移除
val newRepliesSoFar = repliesSoFar + (deviceId -> reading) //将设备加入完成响应列表
if (newStillWaiting.isEmpty) { //如果完成了所有的响应
//发送结果
requester ! DeviceGroup.RespondAllTemperatures(requestId, newRepliesSoFar)
//停止自己
context.stop(self)
} else { //等待其他响应
//重新设置receive
context.become(waitingForReplies(newRepliesSoFar, newStillWaiting))
}
}
}测试
添加DeviceGroupQuerySpec在测试目录的com.lightbend.akka.sample
package com.lightbend.akka.sample
import akka.actor.{ActorSystem, PoisonPill}
import akka.testkit.{TestKit, TestProbe}
import org.scalatest.{BeforeAndAfterAll, FlatSpecLike, Matchers}
import scala.concurrent.duration._
class DeviceGroupQuerySpec(_system: ActorSystem) extends TestKit(_system)
with Matchers with FlatSpecLike with BeforeAndAfterAll {
def this() = this(ActorSystem("DeviceGroupQuerySpec"))
override def afterAll: Unit = {
shutdown(system)
}
"Query" should "return temperature value for working devices" in {
val requester = TestProbe()
val device1 = TestProbe()
val device2 = TestProbe()
//创建一个查询器
val queryActor = system.actorOf(DeviceGroupQuery.props(
actorToDeviceId = Map(device1.ref -> "device1", device2.ref -> "device2"),
requestId = 1,
requester = requester.ref,
timeout = 3.seconds))
//设备期望收到的消息是Device.ReadTemperature(requestId = 0)
device1.expectMsg(Device.ReadTemperature(requestId = 0))
device2.expectMsg(Device.ReadTemperature(requestId = 0))
//给queryActor发送消息,消息为Device.RespondTemperature(requestId = 0, Some(1.0)),发送者是设备
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(1.0)), device1.ref)
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(2.0)), device2.ref)
//期望query发送给请求者的消息为
requester.expectMsg(DeviceGroup.RespondAllTemperatures(
requestId = 1,
temperatures = Map(
"device1" -> DeviceGroup.Temperature(1.0),
"device2" -> DeviceGroup.Temperature(2.0))))
}
"Query" should "return TemperatureNotAvailable for devices with no readings" in {
val requester = TestProbe()
val device1 = TestProbe()
val device2 = TestProbe()
val queryActor = system.actorOf(DeviceGroupQuery.props(
actorToDeviceId = Map(device1.ref -> "device1", device2.ref -> "device2"),
requestId = 1,
requester = requester.ref,
timeout = 3.seconds))
device1.expectMsg(Device.ReadTemperature(requestId = 0))
device2.expectMsg(Device.ReadTemperature(requestId = 0))
queryActor.tell(Device.RespondTemperature(requestId = 0, None), device1.ref)
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(2.0)), device2.ref)
requester.expectMsg(DeviceGroup.RespondAllTemperatures(
requestId = 1,
temperatures = Map(
"device1" -> DeviceGroup.TemperatureNotAvailable,
"device2" -> DeviceGroup.Temperature(2.0))))
}
"Query" should "return temperature reading even if device stops after answering" in {
val requester = TestProbe()
val device1 = TestProbe()
val device2 = TestProbe()
val queryActor = system.actorOf(DeviceGroupQuery.props(
actorToDeviceId = Map(device1.ref -> "device1", device2.ref -> "device2"),
requestId = 1,
requester = requester.ref,
timeout = 3.seconds))
device1.expectMsg(Device.ReadTemperature(requestId = 0))
device2.expectMsg(Device.ReadTemperature(requestId = 0))
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(1.0)), device1.ref)
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(2.0)), device2.ref)
device2.ref ! PoisonPill
requester.expectMsg(DeviceGroup.RespondAllTemperatures(
requestId = 1,
temperatures = Map(
"device1" -> DeviceGroup.Temperature(1.0),
"device2" -> DeviceGroup.Temperature(2.0))))
}
"Query" should "return DeviceTimedOut if device does not answer in time" in {
val requester = TestProbe()
val device1 = TestProbe()
val device2 = TestProbe()
val queryActor = system.actorOf(DeviceGroupQuery.props(
actorToDeviceId = Map(device1.ref -> "device1", device2.ref -> "device2"),
requestId = 1,
requester = requester.ref,
timeout = 1.second))
device1.expectMsg(Device.ReadTemperature(requestId = 0))
device2.expectMsg(Device.ReadTemperature(requestId = 0))
queryActor.tell(Device.RespondTemperature(requestId = 0, Some(1.0)), device1.ref)
requester.expectMsg(DeviceGroup.RespondAllTemperatures(
requestId = 1,
temperatures = Map(
"device1" -> DeviceGroup.Temperature(1.0),
"device2" -> DeviceGroup.DeviceTimedOut)))
}
}将设备组查询加入到Group actor
class DeviceGroup(groupId: String) extends Actor with ActorLogging {
var deviceIdToActor = Map.empty[String, ActorRef]
var actorToDeviceId = Map.empty[ActorRef, String]
var nextCollectionId = 0L
override def preStart(): Unit = log.info("DeviceGroup {} started", groupId)
override def postStop(): Unit = log.info("DeviceGroup {} stopped", groupId)
override def receive: Receive = {
// ... other cases omitted
case RequestAllTemperatures(requestId) =>
context.actorOf(DeviceGroupQuery.props(
actorToDeviceId = actorToDeviceId,
requestId = requestId,
requester = sender(),
3.seconds))
}
}测试在DeviceGroupSpec中添加
"be able to collect temperatures from all active devices" in {
val probe = TestProbe()
val groupActor = system.actorOf(DeviceGroup.props("group"))
groupActor.tell(DeviceManager.RequestTrackDevice("group", "device1"), probe.ref)
probe.expectMsg(DeviceManager.DeviceRegistered)
val deviceActor1 = probe.lastSender
groupActor.tell(DeviceManager.RequestTrackDevice("group", "device2"), probe.ref)
probe.expectMsg(DeviceManager.DeviceRegistered)
val deviceActor2 = probe.lastSender
groupActor.tell(DeviceManager.RequestTrackDevice("group", "device3"), probe.ref)
probe.expectMsg(DeviceManager.DeviceRegistered)
val deviceActor3 = probe.lastSender
// Check that the device actors are working
deviceActor1.tell(Device.RecordTemperature(requestId = 0, 1.0), probe.ref)
probe.expectMsg(Device.TemperatureRecorded(requestId = 0))
deviceActor2.tell(Device.RecordTemperature(requestId = 1, 2.0), probe.ref)
probe.expectMsg(Device.TemperatureRecorded(requestId = 1))
// No temperature for device3
groupActor.tell(DeviceGroup.RequestAllTemperatures(requestId = 0), probe.ref)
probe.expectMsg(
DeviceGroup.RespondAllTemperatures(
requestId = 0,
temperatures = Map(
"device1" -> DeviceGroup.Temperature(1.0),
"device2" -> DeviceGroup.Temperature(2.0),
"device3" -> DeviceGroup.TemperatureNotAvailable)))
}例子总结
actor的特性
- actor最重要的功能是接收消息
- 同一个actor处理消息是顺序执行的,不可能并行处理两个消息
- 不同的actor是并行的
- actor之间的通信是通过消息
- 消息本身不区分是请求还是响应,需要预先定义好通信协议
- 消息可达性不会保证
- 设计actor系统的核心是设计消息
通用的设计方案
- 每个actor类对应一个伴生对象
- 每个伴生对象包含与该actor最密切的消息
- 每个伴生对象包含一个签名为
def props(...): Props的工厂方法 - 消息必须是不可变类型,有参数的使用
final case class,无参数(如答复)的使用case object - 在不同层次要对消息进行重新封装
使用过的api
ActorSystem("iot-system")创建Actor系统Props(actor:Actor)为创建在注册actor的对象ActorSystem.actorOf(pros:Props, name:String):ActorRef在顶层注册actoractor.actorOf(pros:Props, name:String):ActorRef在actor下创建actoroverride def receive = Actor.emptyBehavior不处理任何消息ActorRef ! msg给某个actor发消息sender():ActorRef返回该消息发送者ActorRefActorRef forward trackMsg转发某个消息,发送者不变context.watch(ActorRef)观察某个actor关闭,若关闭将本actor将接收到Terminated消息context.unwatch(ActorRef)取消观察actorval queryTimeoutTimer: Cancellable = context.system.scheduler.scheduleOnce(timeout, self, msg)当达到timeout后,本actor将收到一个msg消息,可以再此做超时处理queryTimeoutTimer.cancel()取消超时监控context.stop(self)关闭当前actorcontext.become重新设置消息处理器(相当于重写了override def receive: Receive)
测试相关
基本骨架
package com.lightbend.akka.sample
import akka.actor.ActorSystem
import akka.testkit.{TestKit, TestProbe}
import org.scalatest.{BeforeAndAfterAll, FlatSpecLike, Matchers}
import scala.concurrent.duration._
class DeviceSpec (_system: ActorSystem) extends TestKit(_system)
with Matchers with FlatSpecLike with BeforeAndAfterAll {
def this() = this(ActorSystem("系统名"))
override def afterAll: Unit = {
shutdown(system)
}
"什么" should "怎么样" in {
//测试内容
}
}相关api
val probe = TestProbe()创建一个测试工具,他可以模拟接收消息,probe.ref返回一个ActorRef类型,发送给probe.ref的消息会可以从probe拿来ActorRef.tell(msg, probe.ref)给ActorRef发送一个消息msg,消息发送者为probe.ref,这样probe就可以拿到ActorRef发送回来的的消息probe.expectMsgType[Msg]probe期望的消息类型为Msg,返回一个Msg实例probe.expectMsg(msg)期望的消息为等于msgshould ===相等断言should !==不相等断言
相关包
//使用
import akka.actor.{Actor, ActorLogging, ActorRef, Cancellable, Props, Terminated}
import scala.concurrent.duration.FiniteDuration
//测试
import akka.actor.{ActorSystem, PoisonPill}
import akka.testkit.{TestKit, TestProbe}
import org.scalatest.{BeforeAndAfterAll, FlatSpecLike, Matchers}
import scala.concurrent.duration._二、一般概念
1、术语,概念
(1)并发和并行
解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。 解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。 解释三:并发是在一台处理器上“同时”处理多个任务,并行是在多台处理器上同时处理多个任务
并发性和并行性是相关的概念,但是有一些小的差别。并发意味着即使两个或多个任务可能不同时执行,两个或更多任务也正在取得进展。这可以例如通过时间分割来实现,其中部分任务按顺序执行并与其他任务的部分混合。另一方面,当执行可以真正同时发生时,会产生并行性。
(2)异步和同步
- 如果调用方在方法返回值或引发异常之前无法进展,则方法调用被认为是同步的。
- 另一方面,异步调用允许调用者在有限数量的步骤之后进行,并且方法的完成可以通过一些额外的机制(可能是已注册的回调,未来或消息)发信号通知。
同步API可能使用阻塞来实现同步,但这不是必需的。一个非常耗费CPU的任务可能会产生与阻塞相似的行为。一般来说,最好使用异步API,因为它们保证系统能够进步。参与者本质上是异步的:一个参与者可以在发送消息之后进行,而不用等待实际的交付发生。
(3)阻塞与非阻塞
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
(4)死锁、饥饿和活锁
死锁就是俩个或多个线程互相等待造成永远被阻塞的状况。
饥渴描述了这样一种状况:一个线程不能够正常访问共享资源造成它不能够前进往下执行。这通常发生在当共享资源因为贪婪的线程长时间不能够被其他线程获得。
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。处于活锁的实体是在不断的改变状态,活锁有可能自行解开。 是指线程1可以使用资源,但它很礼貌,让其他线程先使用资源,线程2也可以使用资源,但它很绅士,也让其他线程先使用资源。这样你让我,我让你,最后两个线程都无法使用资源。
(5)竞争条件(RaceCondition 竞态)
是指多个进程或者线程并发访问和操作同一数据且执行结果与访问发生的特定顺序有关的现象。换句话说,就是线程或进程之间访问数据的先后顺序决定了数据修改的结果。
造成的问题,在极少的情况下得到意外的结果
(6)非阻塞保证Non-blocking Guarantees ( Progress Conditions)
Wait-freedom 如果对一个方法的每次调用在有限的步骤内都能完成,这个方法就被称为”wait-free”
wait-free的方法永远不会阻塞,从而不会发生死锁。从另一个角度来看,由于对方法的调用在有限的步骤内会结束,因此调用者在调用结束后会前进,因此也不会有饥饿。
Lock-freedom Lock-freedom 比wait-freedom更弱。对于lock-free的方法调用,在绝大多数情况下都会在有限步骤后结束。所以对lock-free调用,死锁是不可能的。但是饥饿是可能的,因为并不能保证所有的调用最终都会结束。
Obstruction-freedom Obstruction-freedom是最弱的非阻塞保证。 如果一个方法有机会在一个时间点后单独运行(其它线程不再被执行),那它就会在有限的几步内结束,那这个方法就是obstruction-freedom。所有lock-free的对象都是obstruction-free的,但反过来就不成立了。
2、Actor Systems
actor最佳实践
- actor有效地做好自己的工作,而不会打扰其他人,避免占用资源。也就是说,处理事件,并产生以事件驱动的方式响应(或多个请求)。演员不应关注外部实体
- 消息不可变
- Actor是状态和行为的聚合题
- 设计分层系统,针对每一层考虑异常处理
中止
调用terminate
3、什么是Actor
actor 引用
为了限制actor行为,使用actor引用代替actor对象的引用。这样做好处是:内部封闭和外部消息透明。易于系统管理。
状态
Actor对象通常会包含一些变量,这些变量反映了actor可能处于的状态。这可以是一个明确的状态机(例如使用FSM模块),或者它可以是一个计数器,一组监听器,未决请求等等。这些数据是使actor有价值的东西,他们必须得到保护,免受其他演员的影响。akka演员在概念上每个都有自己的轻量级线程,完全屏蔽了系统的其余部分。
在幕后,Akka将会在真正的线程集上运行一组actor,通常很多actor共享一个线程,并且一个actor的后续调用可能最终会在不同的线程上被处理。Akka确保此实现细节不会影响处理actor的状态的单线程性。
由于内部状态对于演员的操作至关重要,因此状态不一致是致命的。因此,当演员失败并由其Manager重新启动时,状态将从头开始创建,就像首先创建演员一样。这是为了使系统的自我修复能力。
actor也可以从持久化中恢复状态
行为
每次处理消息时,都会将其与当前行为进行匹配。行为意味着一个函数,该函数定义在那个时间点对消息作出的反应所采取的行动,如果客户被授权,则转发一个请求,否则否认。这种行为可能会随时间而改变,例如因为不同的客户随着时间的推移获得授权,或者因为演员可能进入“停止服务”模式,然后又回来。这些更改是通过将它们编码到从行为逻辑读取的状态变量中实现的,或者可以在运行时将函数本身换出,参见成为和不成形操作。然而,在构造actor对象期间定义的初始行为是特殊的,因为重新启动actor会将其行为重置为初始行为。
信箱
Actor的目的是处理消息,这些消息是从其他Actor(或Actor系统外)发送给Actor的。连接发件人和收件人的是Actor的邮箱:每个演员只有一个邮箱,所有发件人都将邮件排入邮箱。排队按照发送操作的时间顺序发生,这意味着不同的actor发送的消息到来具有随机性。另一方面,从同一个演员发送多个消息到同一个目标,将按照相同的顺序排列它们。
有不同的邮箱实施可供选择,默认为FIFO:由参与者处理的消息的顺序匹配它们入队的顺序。这通常是一个很好的默认设置,但是应用程序可能需要优先考虑某些消息。在使用这样的队列时,处理的消息的顺序自然将由队列的算法来定义,并且通常不是FIFO。
An important feature in which Akka differs from some other actor model implementations is that the current behavior must always handle the next dequeued message, there is no scanning the mailbox for the next matching one. Failure to handle a message will typically be treated as a failure, unless this behavior is overridden.
孩子Actor
每个演员都可能是一个监督者:如果它创建子任务委托,它将自动监督他们。孩子的名单保存在演员的上下文中,演员可以访问它。对列表的修改通过创建(context.actorOf(...))或停止(context.stop(child))子项来完成,并且这些操作立即反映出来。实际的创建和终止操作以异步的方式发生在幕后,所以他们不会“阻塞”他们的主管。
主管策略(Supervisor Strategy)
当一个Actor中止时
它将释放它的资源,将所有剩余的邮件从邮箱中删除到系统的“死信邮箱”,这个邮箱将把它们作为DeadLetter转发给EventStream。邮箱然后在主角色引用中用系统邮箱替换,将所有新邮件以DeadLetters方式重定向到EventStream。尽管这是在尽力而为的基础上完成的,但是不要依靠它来构建“有保证的交付”。
不只是默默地倾倒信息的原因是受到我们测试的启发:我们在发送死信的事件总线上注册TestEventListener,并且会为收到的每个死信记录警告——这对于更快解密测试失败非常有帮助。可以想象的是,这个特征也可以用于其他目的。
4、监管和监督
(1)监督意味着什么
正如Actor系统中所描述的,监督描述参与者之间的依赖关系:主管将任务委派给下属,因此必须对他们的失败做出响应。当下属检测到故障(即抛出异常)时,它暂停自身及其所有下属,并向其监督者发送消息,发出信号失败。主管根据要监督的工作性质和失败的性质,可以选择以下四种选择:
Resume:恢复下属,保持其积累的内部状态Restart:重新启动下属,清除其累积的内部状态Stop:永久停止下属Escalate:如果你选择Escalate,可能是因为当前你不知道如何处理这个错误,你把如何处理错误的决策权交给了你的父Actor。如果Actor进行了escalate,那它自己应该也做好被父Actor重启的准备。
一个actor系统将在创建过程中创建了三个actor,分别是/、/user、/system。
延迟重新启动BackoffSupervisor模式
作为内置模式,akka.pattern.BackoffSupervisor实现了所谓的指数退避监督策略,当失败时再次启动子actor,每次重启之间的时间延迟都会增加。
当启动的actor失败时,这种模式非常有用,因为某些外部资源不可用,我们需要再花一些时间来启动。
测试用Actor
class ErrorActor extends Actor {
override def preStart(): Unit = println("preStart执行")
override def postStop(): Unit = println("postStop执行")
override def preRestart(reason: Throwable, message: Option[Any]): Unit = {
super.preRestart(reason, message)
println("preRestart执行")
}
override def postRestart(reason: Throwable): Unit = {
super.postRestart(reason)
println("postRestart执行")
}
override def receive:Receive = {
case _ => throw new Exception
}
}下面的Scala片段显示了如何创建一个backoff supervisor,它在由于失败而停止之后,以3,6,12,24和30秒的间隔增加来启动给定的echo actor:
val system = ActorSystem("testSystem")
val childProps = Props(classOf[ErrorActor])
val supervisor = BackoffSupervisor.props(
Backoff.onStop(
childProps,
childName = "errorActor",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // 增加了20%的“噪音”,以稍微改变间隔
)//.withManualReset // 孩子必须将BackoffSupervisor.Reset发送给其父母
.withDefaultStoppingStrategy //停在任何异常抛出
)
val supervisorActor = system.actorOf(supervisor, name = "errorActorSupervisor")
println("第一次异常")
supervisorActor ! "123"配置监视策略
val supervisor = BackoffSupervisor.props(
Backoff.onFailure(
childProps,
childName = "myEcho",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // adds 20% "noise" to vary the intervals slightly
).withAutoReset(10.seconds) // reset if the child does not throw any errors within 10 seconds
.withSupervisorStrategy(
OneForOneStrategy() {
case _: MyException => SupervisorStrategy.Restart
case _ => SupervisorStrategy.Escalate
}))One-For-One策略与All-For-One策略 有两种基本的监管策略:OneForOneStrategy和AllForOneStrategy,前者意味着你只会处理你子Actor中的错误,并只会影响到出错的那个子Actor,而后者会影响到所有的子Actor。哪种策略更好取决于你的应用程序面临的场景。
5、Actor引用,路径和地址
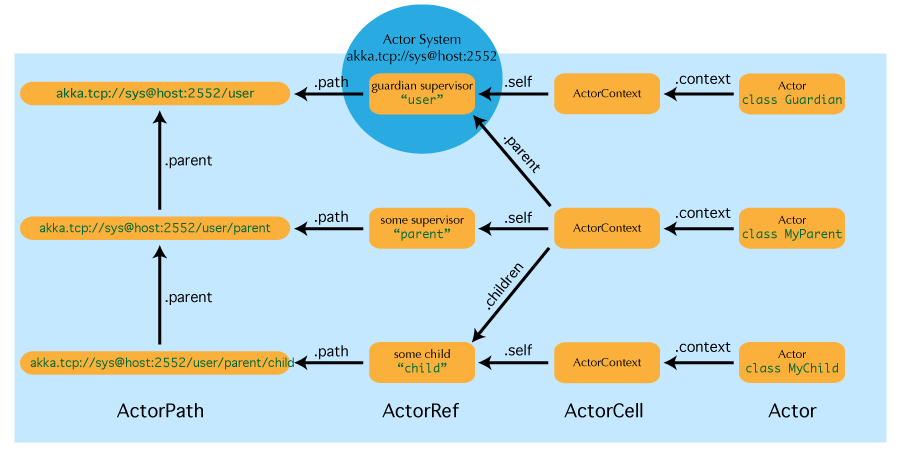
(1)Actor引用
Actor引用是ActorRef的一个子类型,其主要目的是支持发送消息给它所代表的actor。每个actor都可以通过self字段获得其规范(本地)引用;对于发送给其他参与者的所有消息,此引用也作为发送者引用默认包括在内。相反,在消息处理期间,参与者可以通过sender()方法访问表示当前消息发送者的引用。
根据actor系统的配置,支持多种不同类型的actor 引用:
- 纯粹的本地actor引用
- ……
(2)Actor路径
例子
"akka://my-sys/user/service-a/worker1" // purely local
"akka.tcp://[email protected]:5678/user/service-b" // remote(3)如何获得Actor引用?
ActorContext.actorOf返回值sender()返回值,获取发送者引用- 使用相对/绝对路径
context.actorSelection("../brother") ! msgcontext.actorSelection("/user/serviceA") ! msg
- 查询逻辑主体层次结构
context.actorSelection("../*")
(4)Actor参考和路径等价
(5)与远程部署的相互作用
(6)Actor路径的顶层范围
"/user” 是所有用户创建的顶级角色的监护人;在这个下面找到使用ActorSystem.actorOf创建的actor。"/system"是所有系统创建的顶级演员的监护人,例如,日志记录监听器或演员通过配置自动部署在演员系统的开始。"/deadLetters"是死信演员,这是发送到已停止或不存在的参与者的所有消息被重新路由(尽力而为:即使在本地JVM内也可能丢失消息)。"/temp"is the guardian for all short-lived system-created actors, e.g. those which are used in the implementation of ActorRef.ask."/remote"是一个虚拟的路径,在这个虚拟的路径下,所有的主角都是主角是远程主角的参考
6、位置透明性
主要参数在分布式环境下的一些方案和问题 参考
7、Akka和Java内存模型
(1)java内存模型
在Java 5之前,Java内存模型(JMM)没有定义好。共享内存被多个线程访问时,可能会得到各种奇怪的结果
随着Java 5中JSR 133的实现,许多这些问题已经得到解决。MM是一套基于“发生之前”关系的规则,它约束了一个内存访问必须先于另一个发生,反之,当它们被允许发生无序时。这些规则的两个例子是:
- 监视器锁规则
- volatile变量规则
(2)Akka和Java内存模型
通过Akka中的Actor实现,多线程可以通过两种方式在共享内存上执行操作:
- 如果消息被发送给actor(例如,来自另一个actor)。在大多数情况下,消息是不可变的,但如果消息不是一个正确构造的不可变对象,而没有“happens before”规则,接收器收到的消息可能是意外的结果
- 如果一个actor在处理一个消息的时候改变了它的内部状态,并且在处理另外一个消息的时候访问这个状态。使用actor模型你不能保证相同的线程将执行不同的消息的同一个actor。
为了防止对参与者的可视性和重新排序问题,Akka保证以下两个“happens before”规则:
- actor发送规则:发送给actor的消息 发生在同一个actor接收到该消息之前。(同一个actor发送消息是同步的)
- 参与者后续处理规则:处理一个消息发生在同一个参与者处理下一个消息之前。(同一个actor消息处理是同步的)
(3)Future和Java内存模型
(4)actor和共享可变状态
由于Akka在JVM上运行,所以还有一些规则需要遵循。
- 不要将内部的Actor状态并将其暴露给其他线程
- 消息应该是不可变的,这是为了避免共享可变状态陷阱。
8、消息传递可靠性
消息传递在本地和网络上,编程上是一致的。仅仅网络上通信可能出现更大的延迟。这意味着更多可能出错。另一个方面是本地发送只是在同一个JVM中传递对消息的引用,而不会对发送的底层对象有任何限制,而远程传输会限制消息的大小。
(1)一般规则
Akka消息发送的规则(即tell或!方法,这也是ask模式的基础):
- 最多一次交付(不保证保证交付可达)
- 每个 发送者 - 接收者对 的消息是有序的
(2)(本地)消息的规则发送
(3)死信
无法发送的消息(可以确定这些消息)将被发送给一个名为/deadLetters的综合Actor。这种交付发生在尽力而为的基础上;它甚至可能在本地JVM内失败(例如,在演员终止期间)。通过不可靠的网络传输发送的消息将丢失,而不会成为死信。
我应该怎样使用死信? 这个工具的主要用途是调试,特别是如果发送者发送不一致(通常检查死信会告诉你,发件人或收件人被设置错误的地方)。为了达到这个目的,最好避免在可能的情况下发送给deadLetters,也就是不时地用适当的死信日志记录器运行你的应用程序(见下面更多的内容)并清理日志输出。这个练习就像其他的一样 - 需要明智地应用常识:避免发送给被终止的参与者可能会使得发送者的代码复杂化得比调试输出的清晰度更多。
死信服务与所有其他消息发送一样遵循与交付保证相同的规则,因此不能用于实现有保证的交付。
我如何收到死信?
Actor可以在事件流上订阅akka.actor.DeadLetter类,请参阅事件流了解如何做到这一点。那么订阅的演员将从那时起接收在(本地)系统中发布的所有死信。死信不会通过网络传播,如果您想要在一个地方收集它们,则必须为每个网络节点订阅一个角色并手动转发。还要考虑在该节点处生成死信,这可以确定发送操作失败,对于远程发送可以是本地系统(如果没有网络连接可以建立)或远程的(如果你正在发送的演员在那个时间点不存在)。
(通常)并不令人担忧的死信
每当一个演员没有自行决定终止时,就有可能发送给自己的一些消息丢失。在复杂的关机情况下,这种情况通常很容易发生:看到一个akka.dispatch.Terminate消息下降意味着两个终止请求被给予,但当然只有一个可以成功。同样,您可能会看到akka.actor.Terminated来自子节点的消息,同时如果在父节点终止时父节点仍在监视孩子,则会停止以死信形式出现的演员层级。
9、配置
您可以开始使用Akka而无需定义任何配置,因为提供了明智的默认值。稍后,您可能需要修改设置以更改默认行为或适应特定的运行时环境。您可以开始使用Akka而无需定义任何配置,因为提供了明智的默认值。稍后,您可能需要修改设置以更改默认行为或适应特定的运行时环境。
- 日志级别和记录器后端
- 启用远程处理
- 消息序列化器
- 路由器的定义
- 调度员调整
(1)从哪里读取配置
Akka的所有配置都保存在ActorSystem的实例中,或者从外部查看,ActorSystem是配置信息的唯一使用者。在构造一个actor系统的时候,你可以传递一个Config对象,或者不传递ConfigFactory.load()(使用正确的类加载器)。这大致意味着默认是解析在类路径根目录下找到的所有application.conf,application.json和application.properties 。然后,参与者系统将合并在类路径根目录中找到的所有reference.conf资源中,以形成备用配置,即它在内部使用
(2)自定义application.conf
# In this file you can override any option defined in the reference files.
# Copy in parts of the reference files and modify as you please.
akka {
# Loggers to register at boot time (akka.event.Logging$DefaultLogger logs
# to STDOUT)
loggers = ["akka.event.slf4j.Slf4jLogger"]
# Log level used by the configured loggers (see "loggers") as soon
# as they have been started; before that, see "stdout-loglevel"
# Options: OFF, ERROR, WARNING, INFO, DEBUG
loglevel = "DEBUG"
# Log level for the very basic logger activated during ActorSystem startup.
# This logger prints the log messages to stdout (System.out).
# Options: OFF, ERROR, WARNING, INFO, DEBUG
stdout-loglevel = "DEBUG"
# Filter of log events that is used by the LoggingAdapter before
# publishing log events to the eventStream.
logging-filter = "akka.event.slf4j.Slf4jLoggingFilter"
actor {
provider = "cluster"
default-dispatcher {
# Throughput for default Dispatcher, set to 1 for as fair as possible
throughput = 10
}
}
remote {
# The port clients should connect to. Default is 2552.
netty.tcp.port = 4711
}
}