25 分钟
TensorFlow教程(一)
一、安装
1、安装类型
(1)按计算的载体分类
- 仅支持CPU计算
- 对GPU的支持
(2)按运行机制分类
- virtualenv 容器运行
- “native” pip 本地安装
- Docker
- Anaconda
2、在Linux(centos)上安装
参考: https://www.tensorflow.org/install/install_linux 仅介绍本地 pip安装
(1)安装Python环境和pip
yum install -y python-pip python-devel # for Python 2.7
yum install -y python34-pip.noarch python34-devel.x86_64 # for Python 2.7验证
pip -V
pip3 -V(2)安装TensorFlow
选取以下之一
pip install tensorflow # Python 2.7; CPU support (no GPU support)
pip3 install tensorflow # Python 3.n; CPU support (no GPU support)
pip install tensorflow-gpu # Python 2.7; GPU support
pip3 install tensorflow-gpu # Python 3.n; GPU suppor如果以上安装失败,尝试
sudo pip install --upgrade tfBinaryURL # Python 2.7
sudo pip3 install --upgrade tfBinaryURL # Python 3.n(3)验证安装
进入python运行环境
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))不报错即为成功
(4)卸载
pip uninstall tensorflow # for Python 2.7
pip3 uninstall tensorflow # for Python 3.n3、在Windows(win10)上安装
(1)安装py3.5.2
下载地址 https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe
- 在window上,只支持py3.5.x
(2)安装GPU支持CUDA
http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows
验证GPU支持情况
下载程序
https://developer.nvidia.com/cuda-downloads
(3)安装cuDNN v6.0
https://developer.nvidia.com/cudnn 注册,下载,解压,将dll所在目录加入到Path中(解压目录下\cuda\bin)
(4)安装tensorflow
pip3 install --upgrade tensorflow #CPU版
pip3 install --upgrade tensorflow-gpu #GPU版(5)验证安装
python
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))不报错即为成功 若报错请重新查看官网,因为经常有所变动
二、入门
1、TensorFlow入门
TensorFlow 提供两套api
- 低级api是TensorFlow的核心
- 高级api构建于低级api之上,提供更高级的用法,但未稳定
(1)Tensors(张量)
TensorFlow中的中心数据单位是Tensors(张量)。张量由一组成形为任意数量的阵列的原始值组成。张量的等级是其维数。以下是张量的一些例子:
3 # 等级0张量;这是一个具有尺寸[]的标量
[1. ,2., 3.] # 等级1张量;这是一个尺寸为[3]的矢量
[[1., 2., 3.], [4., 5., 6.]] # 等级2张量;具有尺寸为[2,3]的矩阵
[[[1., 2., 3.]], [[7., 8., 9.]]] # 3级张量,尺寸为[2,1,3]2、TensorFlow核心教程
(1)导入TensorFlow
TensorFlow-Python程序的规范导入声明如下:
import tensorflow as tf这使Python可以访问TensorFlow的所有类,方法和符号。
(2)计算图
您可能会认为TensorFlow Core程序由两个不同的部分组成:
- 构建计算图。
- 运行计算图。
计算图是布置在节点图中的一系列TensorFlow操作。我们来构建一个简单的计算图。每个节点采用零个或多个张量作为输入,并产生张量作为输出。一种类型的节点是一个常数。像所有TensorFlow常量一样,它不需要任何输入,它输出一个内部存储的值。我们可以创建两个浮点张量node1和node2,如下所示:
node1 = tf.constant(3.0, dtype=tf.float32) #创建常量张量值为3.0,类型为tf.float32
node2 = tf.constant(4.0) #隐含的类型也为tf.float32
print(node1, node2)输出
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)请注意,打印节点不会按预期输出值3.0和4.0。相反,它们是在评估时分别产生3.0和4.0的节点。要实际评估节点,我们必须在session(会话)中运行计算图。会话封装了TensorFlow运行时的控制和状态。
以下代码创建一个Session对象,然后调用其运行方法运行足够的计算图来评估node1和node2。通过在会话中运行计算图如下: (理解:node可以理解成定义变量,操作可以理解成语句块,最后的session.run可以理解成执行以上的定义产生结果)
sess = tf.Session()
print(sess.run([node1, node2]))我们将看到
[3.0, 4.0]我们可以通过将Tensor节点与操作(操作也是节点)组合来构建更复杂的计算。例如,我们可以添加我们的两个常量节点并生成一个新的图,如下所示:
ode3 = tf.add(node1, node2)
print("node3: ", node3)
print("sess.run(node3): ",sess.run(node3))最后两个print语句生成
node3: Tensor("Add:0", shape=(), dtype=float32)
sess.run(node3): 7.0TensorFlow提供了一个名为TensorBoard的实用程序,可以显示计算图的图片。这是一个屏幕截图,显示TensorBoard如何可视化图形:
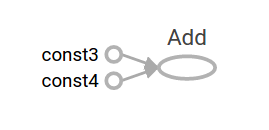
就像这样,这个图并不是特别有趣,因为它总是产生一个恒定的结果。可以将图形参数化为接受外部输入,称为占位符。占位符是以后提供价值的承诺。 (理解:占位符可以理解成函数的输入和输出)
a = tf.placeholder(tf.float32) #定义一个占位符,元素类型为32位浮点数
b = tf.placeholder(tf.float32)
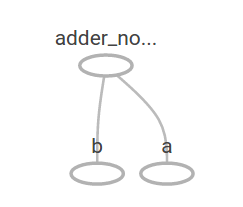
adder_node = a + b # + 等价于 tf.add(a, b)前面的三行有点像一个函数或一个lambda,其中我们定义了两个输入参数(a和b),然后对它们进行一个操作。我们可以通过使用feed_dict参数来指定多个输入的图表来指定为这些占位符提供具体值的Tensors:
输出
7.5
[ 3. 7.]在TensorBoard中,图形如下所示:
我们可以通过添加另一个操作来使计算图更加复杂。例如,
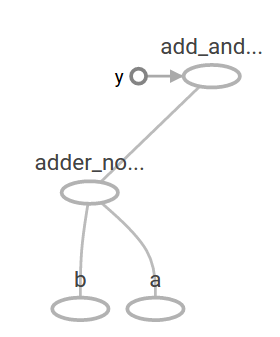
add_and_triple = adder_node * 3.0 #再附加乘的操作
print(sess.run(add_and_triple, {a: 3, b:4.5})) #执行计算输出
22.5前面的计算图在TensorBoard中将如下所示:
 在机器学习中,我们通常会想要一个可以接受任意输入的模型,比如上面的一个。为了使模型可训练,我们需要能够修改图形以获得具有相同输入的新输出。变量允许我们向图表添加可训练的参数。它们的构造类型和初始值
在机器学习中,我们通常会想要一个可以接受任意输入的模型,比如上面的一个。为了使模型可训练,我们需要能够修改图形以获得具有相同输入的新输出。变量允许我们向图表添加可训练的参数。它们的构造类型和初始值
W = tf.Variable([.3], dtype=tf.float32) #创建一个变量
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32) #创建一个占位符
linear_model = W * x + b #创建一个线性模型当调用tf.constant时,常量被初始化,他们的值永远不会改变。相比之下,当您调用tf.Variable时,变量不会被初始化。要初始化TensorFlow程序中的所有变量,必须显式调用特殊操作,如下所示:
init = tf.global_variables_initializer()
sess.run(init)重要的是实现init是TensorFlow子图的一个句柄,它初始化所有的全局变量。在我们调用sess.run之前,这些变量是未初始化的。
由于x是占位符,我们可以同时评估x的几个值的linear_model,如下所示:
print(sess.run(linear_model, {x:[1,2,3,4]}))输出
[ 0. 0.30000001 0.60000002 0.90000004]我们创建了一个模型,但是我们不知道它是多么好。为了评估培训数据模型,我们需要一个y占位符来提供所需的值,我们需要编写一个损失函数(代价函数)。
损失函数测量当前模型与提供的数据之间的距离。我们将使用线性回归的标准损耗模型,它将当前模型和提供的数据之间的deltas 的平方和。linear_model - y创建一个向量,其中每个元素都是对应的示例的误差增量。我们调用tf.square来对误差做平方。然后,我们求所有误差平方的和,创建一个单一的标量,使用tf.reduce_sum抽象出所有示例的误差:
y = tf.placeholder(tf.float32) #创建占位符
squared_deltas = tf.square(linear_model - y) #求delta^2
loss = tf.reduce_sum(squared_deltas) #求和,计算出最终误差
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]})) #执行求出损失最后输出误差值为:
23.66我们可以通过手动改进将W和b的值重新分配到-1和1的完美值。变量初始化的值为提供给tf.Variable函数的值,但可以使用tf.assign等操作进行更改。例如,W = -1和b = 1是我们模型的最优参数。我们可以相应地改变W和b:
fixW = tf.assign(W, [-1.]) #修改W的值为-1
fixb = tf.assign(b, [1.]) #修改b的值为1
sess.run([fixW, fixb]) #执行更改
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]})) ##重新计算损失函数输出
0.0我们猜测W和B的“完美”值,但机器学习的全部要点是自动找到正确的模型参数。我们将在下一节中展示如何完成这一点。
(3)tf.train API
机器学习的完整讨论超出了本教程的范围。然而,TensorFlow提供了optimizers(优化器),可以缓慢地更改每个变量,以便最小化损失函数。最简单的优化器是梯度下降( gradient descent)。它根据相对于该变量的损失导数的大小修改每个变量。通常,手动计算符号导数是冗长乏味且容易出错的。因此,TensorFlow可以使用函数tf.gradients自动生成仅给出模型描述的导数。为了简单起见,优化器通常为您做这个。例如,
optimizer = tf.train.GradientDescentOptimizer(0.01) #创建梯度下降优化器,学习率为0.01
train = optimizer.minimize(loss) #该优化器为最小化损失函数
sess.run(init) # 将值重置为不正确的默认值
for i in range(1000): #训练1000次
sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
print(sess.run([W, b])) #输出训练结果训练结果
[array([-0.9999969], dtype=float32), array([ 0.99999082],
dtype=float32)]现在我们已经完成了实际的机器学习!尽管这样做简单的线性回归并不需要太多的TensorFlow核心代码,但更复杂的模型和方法将数据输入到模型中需要更多的代码。因此,TensorFlow为常见的模式,结构和功能提供了更高级别的抽象。我们将在下一节中学习如何使用其中的一些抽象。
完整的线性模型训练样例
import numpy as np
import tensorflow as tf
# Model parameters 模型参数
W = tf.Variable([.3], dtype=tf.float32) #待训练的参数
b = tf.Variable([-.3], dtype=tf.float32)
# Model input and output 模型输入输出
x = tf.placeholder(tf.float32)
linear_model = W * x + b #构建模型
y = tf.placeholder(tf.float32)
# loss 损失函数
loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares
# optimizer 初始化优化器
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# training data 加载训练数据
x_train = [1,2,3,4]
y_train = [0,-1,-2,-3]
# training loop 循环训练
init = tf.global_variables_initializer() #加载全局变量初始化器
sess = tf.Session() #获取会话
sess.run(init) # reset values to wrong初始化变量为错误值
for i in range(1000): #循环训练
sess.run(train, {x:x_train, y:y_train})
# evaluate training accuracy 评估培训准确性
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
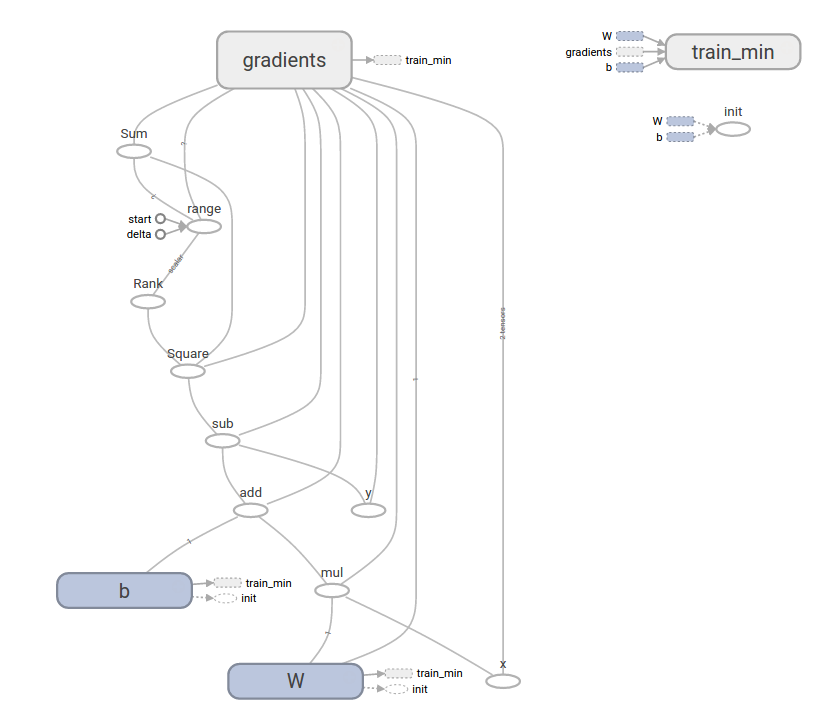
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))请注意,损失是非常小的数字(接近零)。如果您运行此程序,您的损失将不会完全相同,因为模型是用随机值初始化的。
这个更复杂的程序仍然可以在TensorBoard中进行可视化
(4)tf.contrib.learn
tf.contrib.learn是一个高级TensorFlow库,它简化了机器学习的机制,其中包括:
- 运行训练循环
- 运行评估循环
- 管理数据集
- 管理喂养(managing feeding)
tf.contrib.learn定义了许多常见的模型。
基本用法
注意tf.contrib.learn可以简化线性回归程序:
import tensorflow as tf
# NumPy is often used to load, manipulate and preprocess data.
# NumPy通常用于加载,操纵和预处理数据。
import numpy as np
# Declare list of features. We only have one real-valued feature. There are many
# other types of columns that are more complicated and useful.
# 声明特征列表。我们只有一个实数的特征。
# 当然还有其他的更加复杂和有用的列类型
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# An estimator is the front end to invoke training (fitting) and evaluation
# (inference). There are many predefined types like linear regression,
# logistic regression, linear classification, logistic classification, and
# many neural network classifiers and regressors. The following code
# provides an estimator that does linear regression.
# 估计器是一个实现训练和评估的前端。有许多预定义类型,
# 如线性回归, 逻辑回归,线性分类,物流分类和很多神经网络分类器和回归器。
# 以下代码提供一个进行线性回归的估计
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow provides many helper methods to read and set up data sets.
# Here we use two data sets: one for training and one for evaluation
# We have to tell the function how many batches
# of data (num_epochs) we want and how big each batch should be.
# TensorFlow提供了许多帮助方法来读取和设置数据集。
# 这里我们使用两个数据集:一个用于训练,一个用于评估
# 我么还有告诉函数有多少批次数据(num_epochs),每一批次数据有多大
x_train = np.array([1., 2., 3., 4.]) #训练集数据
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.]) #验证集数据
y_eval = np.array([-1.01, -4.1, -7, 0.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x_train}, y_train,
batch_size=4,
num_epochs=1000)
eval_input_fn = tf.contrib.learn.io.numpy_input_fn(
{"x":x_eval}, y_eval, batch_size=4, num_epochs=1000)
# We can invoke 1000 training steps by invoking the method and passing the
# training data set.
# 我们可以通过调用方法和传递训练数据集来实现1000此训练。
estimator.fit(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did.
# 在这里我们评估我们的模型做得如何。
train_loss = estimator.evaluate(input_fn=input_fn)
eval_loss = estimator.evaluate(input_fn=eval_input_fn)
print("train loss: %r"% train_loss)
print("eval loss: %r"% eval_loss)运行时,它会产生
train loss: {'loss': 2.0180224e-08, 'global_step': 1000}
eval loss: {'loss': 0.0025395651, 'global_step': 1000}请注意我们的eval数据的损失是多少,但仍然接近于零。这意味着我们正在学习。
自定义模型
tf.contrib.learn不会将您锁定到其预定义的模型中。假设我们想创建一个没有内置到TensorFlow中的自定义模型。我们仍然可以保留tf.contrib.learn的数据集,饲养,培训等的高级抽象。为了说明,我们将使用我们对较低级别TensorFlow API的了解,展示如何使用LinearRegressor实现我们自己的等效模型。
要定义使用tf.contrib.learn的自定义模型,我们需要使用tf.contrib.learn.Estimator。tf.contrib.learn.LinearRegressor实际上是一个tf.contrib.learn.Estimator的子类。我们只是给Estimator提供一个函数model_fn来告诉tf.contrib.learn如何评估预测,训练步骤和损失,而不是分类Estimator。代码如下:
import numpy as np
import tensorflow as tf
# Declare list of features, we only have one real-valued feature
def model(features, labels, mode):
# Build a linear model and predict values
# 构建一个线性回归模型和预测值
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# Loss sub-graph
# 损失函数子图
loss = tf.reduce_sum(tf.square(y - labels))
# Training sub-graph
# 训练子图
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps connects subgraphs we built to the
# appropriate functionality.
# ModelFnOps将我们构建的子图连接到适当的功能。
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# define our data sets
# 定义数据集
x_train = np.array([1., 2., 3., 4.])
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.])
y_eval = np.array([-1.01, -4.1, -7, 0.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x_train}, y_train, 4, num_epochs=1000)
eval_input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x_eval}, y_eval, 4, num_epochs=1000)
# train
# 训练
estimator.fit(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did.
# 这儿我们将评估我们的模型表现如何
train_loss = estimator.evaluate(input_fn=input_fn)
eval_loss = estimator.evaluate(input_fn=eval_input_fn)
print("train loss: %r"% train_loss)
print("eval loss: %r"% eval_loss)运行时,它会产生
train loss: {'global_step': 1000, 'loss': 6.4150553e-11}
eval loss: {'global_step': 1000, 'loss': 0.010101151}请注意,自定义model()函数的内容与下一级API的手动模型训练循环非常相似。
下一步
现在您已经了解了TensorFlow的基础知识。我们有更多的教程可以看看,了解更多。如果您是机器学习的初学者,请参阅MNIST的初学者,否则请查看深入MNIST的专家。
3、MNIST机器学习入门
http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html https://www.tensorflow.org/get_started/mnist/beginners
(1)MNIST数据集
当我们开始学习编程的时候,第一件事往往是学习打印”Hello World”。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片(大小为28*28),它也包含每一张图片对应的标签,告诉我们这个是数字几。
下载地址:http://yann.lecun.com/exdb/mnist/ 注意:下载的四个文件不是可以直接打开的普通图片文件,而是自定义的格式,格式参见网站底部
TensorFlow提供了自动下载读取该数据集的函数:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#源码参见:https://tensorflow.googlesource.com/tensorflow/+/master/tensorflow/examples/tutorials/mnist/input_data.py这两行代码会下载4个文件并生成两组数据:60000行训练数据集(mnist.train)和 10000行测试数据集(mnist.test) 讲过处理后的结构是:
mnist.train.images为尺寸为[60000, 784]的张量,60000表示有60000张图片,748(28*28)表示一张图片,在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。mnist.train.labels是一个 [60000, 10] 的数字矩阵,表示对应图片的标签- 测试集类似
(2)Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9。我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%但是判断它是8的概率是5%(因为8和9都有上半部分的小圆),然后给予它代表其他数字的概率更小的值。
这是一个使用softmax回归(softmax regression)模型的经典案例。softmax模型可以用来给不同的对象分配概率。即使在之后,我们训练更加精细的模型时,最后一步也需要用softmax来分配概率。
softmax回归(softmax regression)分两步:第一步
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。
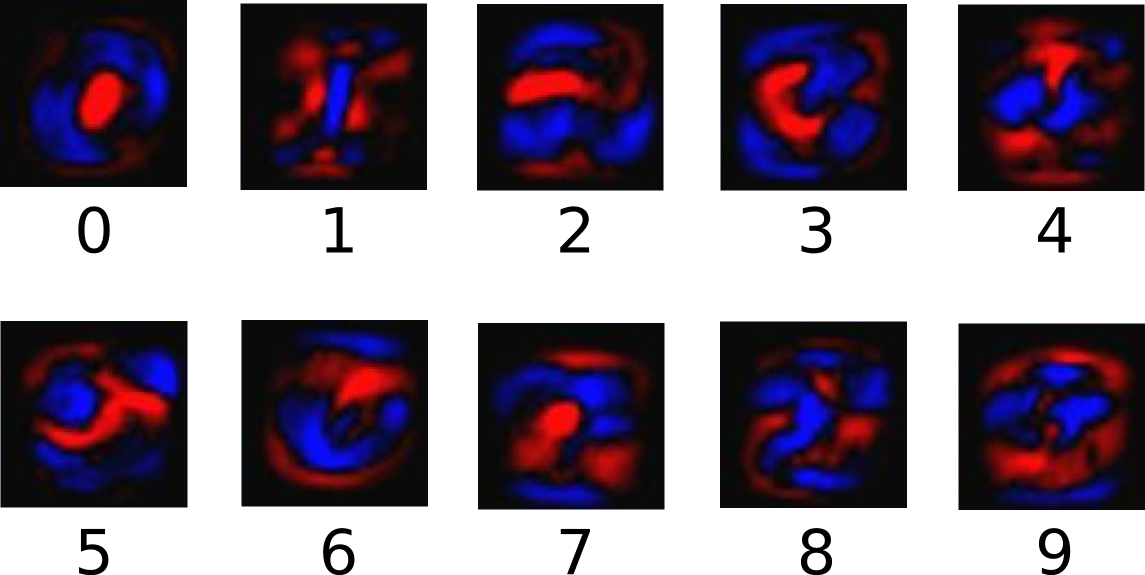
下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值。红色代表负数权值,蓝色代表正数权值。
 我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为
$$
\text{evidence}_i = \sum_j W_{i,~ j} x_j + b_i
$$
我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为
$$
\text{evidence}_i = \sum_j W_{i,~ j} x_j + b_i
$$
其中\(W_i\)代表权重, \(b_i\)代表数字 i 类的偏置量,\(j\) 代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y: $$ y = \text{softmax}(\text{evidence}) $$ 这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为: $$ \text{softmax}(x) = \text{normalize}(\exp(x)) $$
展开等式右边的子式,可以得到: $$ \text{softmax}(x)_i = \frac{\exp(x_i)}{\sum_j \exp(x_j)} $$ 但是更多的时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。(更多的关于Softmax函数的信息,可以参考Michael Nieslen的书里面的这个部分,其中有关于softmax的可交互式的可视化解释。)
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:
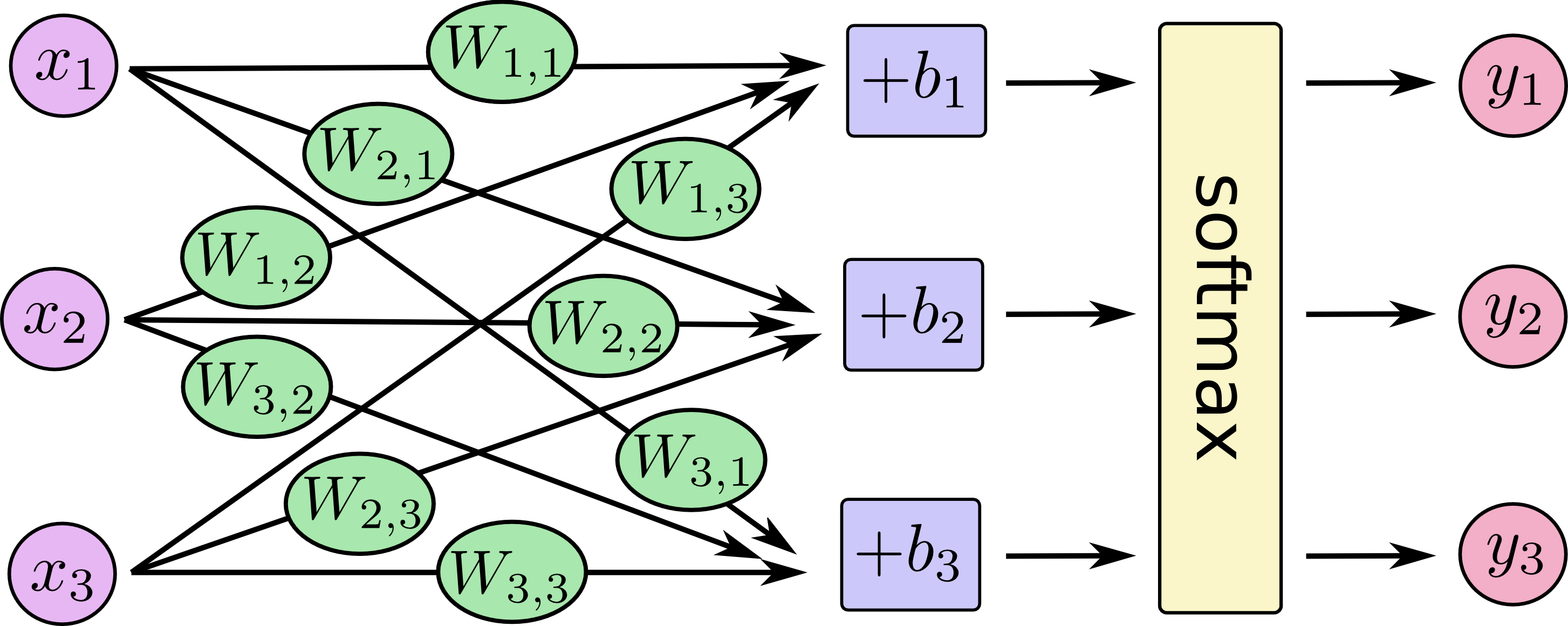 如果把它写成一个等式,我们可以得到:
如果把它写成一个等式,我们可以得到:
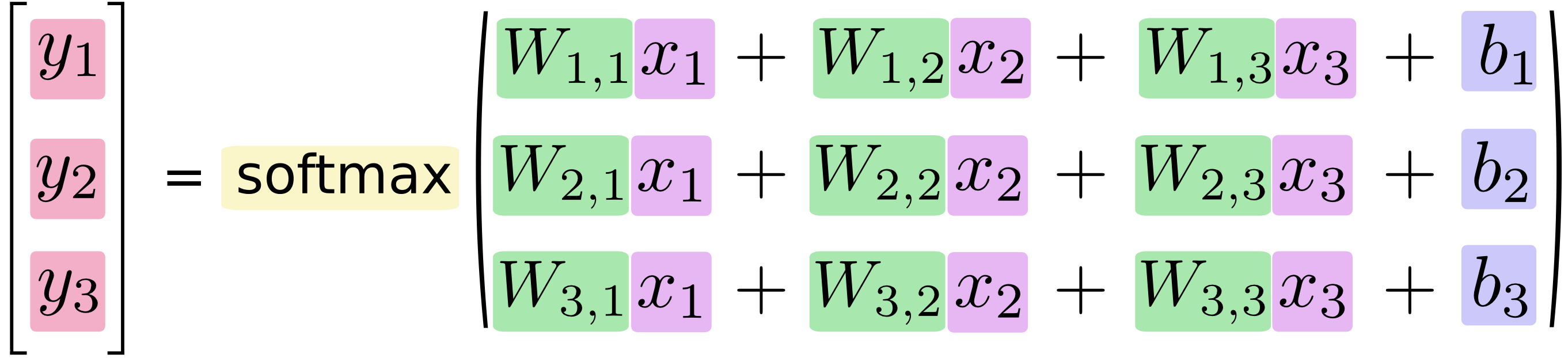 我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)
我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)
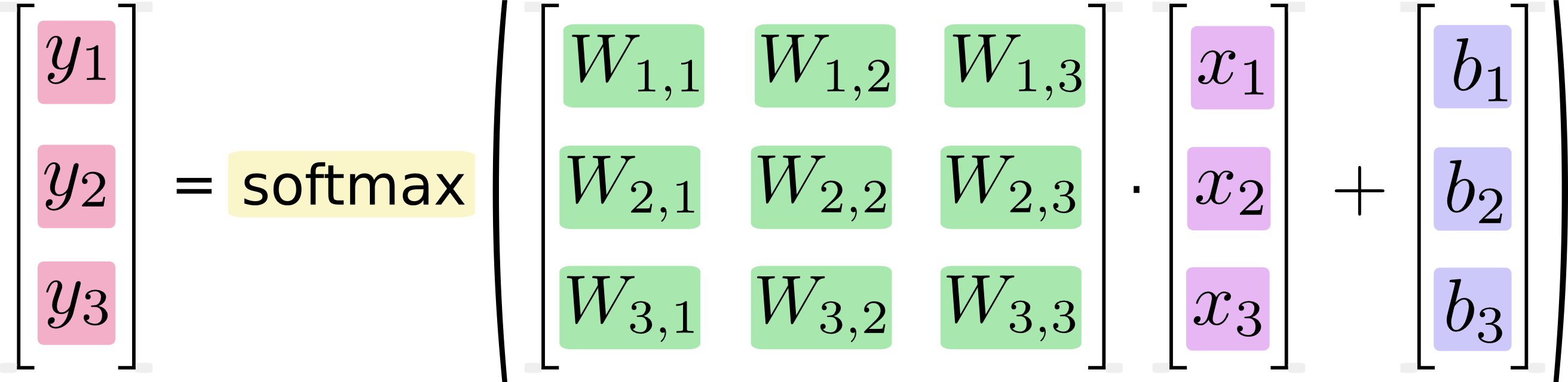 更进一步,可以写成更加紧凑的方式:
$$
y = \text{softmax}(Wx + b)
$$
现在我们来看看TensorFlow可以使用的东西。
更进一步,可以写成更加紧凑的方式:
$$
y = \text{softmax}(Wx + b)
$$
现在我们来看看TensorFlow可以使用的东西。
(3)实现回归模型
为了用python实现高效的数值计算,我们通常会使用函数库,比如NumPy,会把类似矩阵乘法这样的复杂运算使用其他外部语言实现。不幸的是,从外部计算切换回Python的每一个操作,仍然是一个很大的开销。如果你用GPU来进行外部计算,这样的开销会更大。用分布式的计算方式,也会花费更多的资源用来传输数据。
TensorFlow也把复杂的计算放在python之外完成,但是为了避免前面说的那些开销,它做了进一步完善。Tensorflow不单独地运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。(这样类似的运行方式,可以在不少的机器学习库中看到。)
使用TensorFlow之前,首先导入它:
import tensorflow as tf我们通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder("float", [None, 784])x不是一个特定的值,而是一个占位符placeholder,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是[None,784 ]。(这里的None表示此张量的第一个维度可以是任何长度的。)
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),但TensorFlow有一个更好的方法来表示它们:Variable 。 一个Variable代表一个可修改的张量,存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用Variable表示。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b。因为我们要学习W和b的值,它们的初值可以随意设置。
注意,W的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。b的形状是[10],所以我们可以直接把它加到输出上面。
现在,我们可以实现我们的模型啦。只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)首先,我们用tf.matmul(X,W)表示x乘以W,对应之前等式里面的\(Wx\),这里x是一个2维张量拥有多个输入。然后再加上b,把和输入到tf.nn.softmax函数里面。
至此,我们先用了几行简短的代码来设置变量,然后只用了一行代码来定义我们的模型。TensorFlow不仅仅可以使softmax回归模型计算变得特别简单,它也用这种非常灵活的方式来描述其他各种数值计算,从机器学习模型对物理学模拟仿真模型。一旦被定义好之后,我们的模型就可以在不同的设备上运行:计算机的CPU,GPU,甚至是手机!
(4)训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的。其实,在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。但是,这两种方式是相同的。
一个非常常见的,非常漂亮的成本函数是“交叉熵”(cross-entropy)。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。它的定义如下:
$$
H_{y’}(y) = -\sum_i y’_i \log(y_i)
$$
y 是我们预测的概率分布, y' 是实际的分布(我们输入的one-hot vector)。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。更详细的关于交叉熵的解释超出本教程的范畴,但是你很有必要好好理解它。
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])然后我们可以用 \(-\sum y’\log(y)\) 计算交叉熵:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))首先,用 tf.log 计算 y 的每个元素的对数。接下来,我们把 y_ 的每一个元素和 tf.log(y_) 的对应元素相乘。最后,用 tf.reduce_sum 计算张量的所有元素的总和。(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能。
现在我们知道我们需要我们的模型做什么啦,用TensorFlow来训练它是非常容易的。因为TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。当然TensorFlow也提供了其他许多优化算法:只要简单地调整一行代码就可以使用其他的算法。
TensorFlow在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减少成本。
现在,我们已经设置好了我们的模型。在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variables()现在我们可以在一个Session里面启动我们的模型,并且初始化变量:
sess = tf.Session()
sess.run(init)然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行train_step。
使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练。在理想情况下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一次训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性。
(5)评估我们的模型
那么我们的模型性能如何呢?
首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,我们计算所学习到的模型在测试数据集上面的正确率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})这个最终结果值应该大约是91%。
这个结果好吗?嗯,并不太好。事实上,这个结果是很差的。这是因为我们仅仅使用了一个非常简单的模型。不过,做一些小小的改进,我们就可以得到97%的正确率。最好的模型甚至可以获得超过99.7%的准确率!(想了解更多信息,可以看看这个关于各种模型的性能对比列表。)
4、MNIST机器学习深入
卷积神经网络简介:https://zhuanlan.zhihu.com/p/25249694 http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html https://www.tensorflow.org/get_started/mnist/pros
### 步骤1:加载数据 ###
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 查看数据
# mnist.train.images为训练数据
print(mnist.train.images.ndim) #获取数据维度
print(mnist.train.images.shape) #获取数组各个维度的大小
print(mnist.train.labels.shape)
# 引入tf库
import tensorflow as tf
sess = tf.InteractiveSession() #创建交互式会话
### 步骤2:创建输入训练样本数据和标签的占位符 ###
# 创建训练数据所用的占位符,维度为2,第一维为任意在运行时指定,
# 取决于批次batch
x = tf.placeholder("float", shape=[None, 784]) #输入占位符
y_ = tf.placeholder("float", shape=[None, 10]) #数据标签(输出)占位符
### 步骤3:创建模型参数 ###
# 创建训练特征变量(权重W和偏置b)
# 创建权重的函数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 创建偏置的的函数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#第一层卷积的参数
W_conv1 = weight_variable([5, 5, 1, 32]) #5*5滤波器,输入通道为1,输出通道为32
b_conv1 = bias_variable([32])
#第二层卷积的参数
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
#密集连接层的参数
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
#输出层的参数
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
### 步骤4:构建假设函数模型y ###
# 卷积和池化函数
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 构建y的模型
#对输入x重塑成1通道的张量
x_image = tf.reshape(x, [-1,28,28,1])
# 第一层卷积和池化降维
# 公式为:ReLU激活(卷积(x,w) + b)
#输入:1*28*28 输出为32*14*14
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1) #2*2降维,
# 第二层卷积和池化降维
#输入:32*14*14 输出为:64*7*7
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#密集连接层
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #展开64*7*7的张量
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
#Dropout层,防止过拟合
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#输出层
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
### 步骤5:构造代价函数 ###
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
### 步骤6:训练模型 ###
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#初始化、训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
### 步骤7:评估模型 ###
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))5、tf.contrib.learn快速开始
(1)描述
- 以下使用tf的高级api完成深度神经网络(DNN)的构建、训练、评价
- 问题:为对三种花的分类
- 数据:格式为cvs,每行为花的参数(萼片长度,萼片宽度,花瓣长度,花瓣宽度,和花的品种)
(2)python3代码
import os
import urllib.request
import numpy as np
import tensorflow as tf
# 数据集
IRIS_TRAINING = "iris_training.csv"
IRIS_TRAINING_URL = "http://download.tensorflow.org/data/iris_training.csv"
IRIS_TEST = "iris_test.csv"
IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
# 主函数
def main():
### 下载训练和测试集 ###
# 如果训练集和测试集没有不存在,下载它们。
if not os.path.exists(IRIS_TRAINING):
raw = urllib.request.urlopen(IRIS_TRAINING_URL).read()
# print(type(raw))
# print(len(raw))
# print(raw)
with open(IRIS_TRAINING, "wb") as f:
f.write(raw)
if not os.path.exists(IRIS_TEST):
raw = urllib.request.urlopen(IRIS_TEST_URL).read()
with open(IRIS_TEST, "wb") as f:
f.write(raw)
### 加载训练和测试集 ###
# 载入数据集。
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING, #文件名
target_dtype=np.int, #标签的数据类型
features_dtype=np.float32) #输入特征的数据类型
# print(training_set)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
### 构建深度神经网络分类器 ###
# 指定训练集特征的数目和数据类型
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# 构建3层DNN(深度神经网络,全连接),分别为10,20,10个节点。
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
### 描述训练输入管道 ###
def get_train_inputs():
x = tf.constant(training_set.data)
y = tf.constant(training_set.target)
return x, y
### 将模型连接到数据 ###
classifier.fit(input_fn=get_train_inputs, steps=2000)
# 定义测试输入数据x和标签y
def get_test_inputs():
x = tf.constant(test_set.data)
y = tf.constant(test_set.target)
return x, y
### 评估模型精度 ###
# 评估准确性
accuracy_score = classifier.evaluate(input_fn=get_test_inputs,
steps=1)["accuracy"]
print("\nTest Accuracy: {0:f}\n".format(accuracy_score))
### 应用训练好的模型 ###
# 分类两个新鲜花样本。
def new_samples():
return np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
predictions = list(classifier.predict(input_fn=new_samples))
print(
"New Samples, Class Predictions: {}\n"
.format(predictions))
if __name__ == "__main__":
main()(3)程序流程
下载训练和测试集
加载训练和测试集
使用tf.contrib.learn.datasets.base.load_csv_with_header(...)来加载数据
参数说明
- filename,文件位置
- target_dtype,数据集的目标值(标签)的numpy数据类型
- features_dtype, 它使用数据集的特征值(特征)的numpy数据类型。
在tf.contrib.learn 数据集表示为namedtuple的形式,您可以通过数据和目标字段访问特征数据和目标值。这里,training_set.data和training_set.target分别包含训练集的特征数据和目标值,test_set.data和test_set.target包含测试集的要素数据和目标值。
稍后,在“将DNNC分类器安装到Iris训练数据”中,您将使用training_set.data和training_set.target来训练您的模型,并在“评估模型精度”中使用test_set.data和test_set.target 。但首先,您将在下一节中构建您的模型。
构建深度神经网络分类器
tf.contrib.learn提供了各种预定义的模型,称为估算器( Estimators),您可以使用“开箱即用”来对数据运行培训和评估操作。在这里,您将配置深层神经网络分类器模型以适应Iris数据。使用tf.contrib.learn,您可以使用几行代码实例化tf.contrib.learn.DNNClassifier
- 首先定义特征列的数目和数据类型,
tf.contrib.layers.real_valued_column是用于构建要素列的适当函数。 - 然后
tf.contrib.learn.DNNClassifier使用以下参数创建feature_columns=feature_columnshidden_units=[10, 20, 10]:三个隐藏层,分别含有10,20和10个神经元。n_classes = 3:三个目标分类器,代表三分类问题。model_dir=/tmp/iris_model:TensorFlow将在模型训练期间保存检查点数据的目录。有关使用TensorFlow进行日志和监视的更多信息,请看:Logging and Monitoring Basics with tf.contrib.learn
描述训练输入管道
tf.contrib.learnAPI使用输入函数来为模型提供训练数据。在这个例子中,数据足够小,可以存储在TensorFlow常量中。以下代码生成最简单的输入管道:
# Define the training inputs
def get_train_inputs():
x = tf.constant(training_set.data)
y = tf.constant(training_set.target)
return x, y将模型连接到数据
现在您已经配置了DNN分类器模型,您可以使用fit方法将其适用于Iris训练数据。通过get_train_inputs作为input_fn,以及训练的步骤数(here,2000):
classifier.fit(input_fn=get_train_inputs, steps=2000)
模型的状态保留在分类器中,这意味着如果你喜欢,你可以迭代地训练。例如,以上等价于以下内容:
classifier.fit(x=training_set.data, y=training_set.target, steps=1000)
classifier.fit(x=training_set.data, y=training_set.target, steps=1000)评估模型精度
使用classifier.evaluate(input_fn=get_test_inputs,steps=1),返回模型的各个评估参数的值的字典
应用训练好的模型
classifier.predict(input_fn=new_samples)