4 分钟
Spark SQL源码阅读
Spark 版本: 2.3.4 https://www.jianshu.com/u/60e8e974eb07 http://www.jasongj.com/spark/rbo/
测试源码
// $ spark-shell
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StructField, StructType, StringType, LongType}
// 测试表1: user_fact 用户实时表
val userFactSchema = new StructType(Array(
new StructField("user_id", LongType, true),
new StructField("vv", LongType, true),
new StructField("fun_cnt", LongType, true)))
val userFactRows = Seq(Row(1L, 10L, 100L))
val userFactRDD = spark.sparkContext.parallelize(userFactRows)
val userFactDF = spark.createDataFrame(userFactRDD, userFactSchema)
userFactDF.createOrReplaceTempView("user_fact");
// 测试表2: user_dim 用户维度表
val userDim = Seq((1L, "xiaoming")).toDF("id", "nickname")
userDim.createOrReplaceTempView("user_dim")
// 执行sql语句
val res = spark.sql("""
select
*
from
user_fact
inner join user_dim
on user_fact.user_id = user_dim.id
""")
res.show()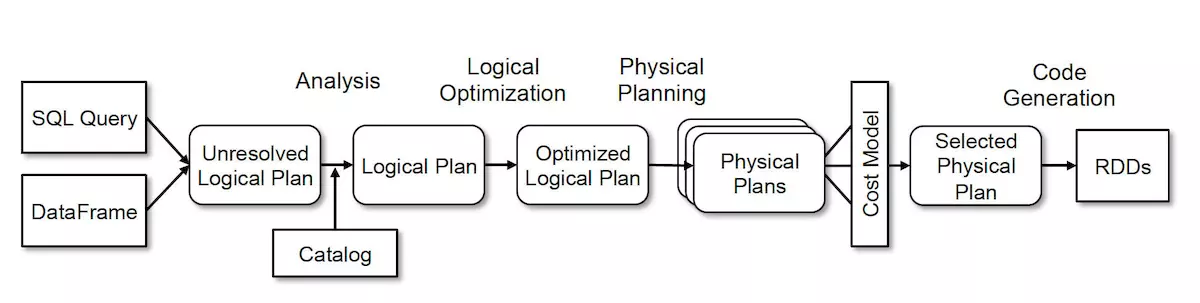
SparkSession
- sessionState 的构造方法一般是
org.apache.spark.sql.internal.BaseSessionStateBuilder#build
SQL解析生成未解决的逻辑计划
SparkSqlParser
源码中的spark对象是SparkSession的一个实例。Spark Doc是说:
本类是使用Dataset和DataFrame API编程Spark的入口点。
调用过程
org.apache.spark.sql.SparkSession#sql
/**
* Executes a SQL query using Spark, returning the result as a `DataFrame`.
* The dialect that is used for SQL parsing can be configured with 'spark.sql.dialect'.
*
* @since 2.0.0
*/
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parsePlan
/** Creates LogicalPlan for a given SQL string. */
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}org.apache.spark.sql.execution.SparkSqlParser#parse
protected override def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
super.parse(substitutor.substitute(command))(toResult)
}org.apache.spark.sql.internal.VariableSubstitution#substitute (非核心,主要用来处理sql中 ${var}、${system:var}、${env:var}的)
def substitute(input: String): String = {
if (conf.variableSubstituteEnabled) {
reader.substitute(input)
} else {
input
}
}org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parse
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
}上述代码应用到了一个第三方开源语法分析器 antlr4
该语法分析器的使用流程是:
- 定义一个语法定义文件(后缀名
.g4) - 通过antlr4的编译器把g4文件生成Java代码,核心文件如下(开启vistor)
- XxxParser
- XxxLexer
- XxxBaseVistor
- XxxVisitor
- 继承 XxxBaseVistor 实现逻辑,将用户输入经过antlr4创建的语法树,通过遍历转换为内部数据结构
过程如下
- log 到 try 之间的代码就是构造读取输入sql,构造ANTLR4语法树。
- try 内的代码是 解析这可语法树构造 unresolved logical plan
- 首先以 SSL 模式尝试
- 失败后使用 LL 模式
toResult 的传参位置在
org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parsePlan实现如下parser => astBuilder.visitSingleStatement(parser.singleStatement()) match { case plan: LogicalPlan => plan case _ => val position = Origin(None, None) throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position) }astBuilder 的类型是
org.apache.spark.sql.catalyst.parser.AstBuilder,其核心作用是将ANTLR4语法树转化为Spark内部的LogicalPlan
AstBuilder 解析语法树
AstBuilder 是 SqlBaseBaseVisitor 的 实现类,用于在遍历SQL语法树的过程中创建逻辑计划
具体实现细节参见 源码
逻辑计划 LogicalPlan
AstBuilder 返回的逻辑计划本质上是一棵树,进一步树是一个数的根节点。树的继承结构如下:
org.apache.spark.sql.catalyst.trees.TreeNode
^
|
org.apache.spark.sql.catalyst.plans.QueryPlan
^
|
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
主要子类说明:
- LeafNode children.size == 0 主要是Relation节点,与数据源有关
- UnaryNode children.size == 1 主要对数据进行transform包括
- BinaryNode children.size == 2 主要是Join
- Union children.size 不定 包含多个子节点
- Command: children.size == 0 主要是DDL、DML操作,包括Insert
执行计划——创建QueryExecution
回到 org.apache.spark.sql.SparkSession#sql,sessionState.sqlParser.parsePlan(sqlText)返回的就是一个未解决的逻辑计划
/**
* Executes a SQL query using Spark, returning the result as a `DataFrame`.
* The dialect that is used for SQL parsing can be configured with 'spark.sql.dialect'.
*
* @since 2.0.0
*/
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}org.apache.spark.sql.Dataset#ofRows
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}qe 其类型为
org.apache.spark.sql.execution.QueryExecution,官方doc表示,该类的存在是方面设计和调试,该类持有SparkSession和LogicalPlan的引用。创建方法为org.apache.spark.sql.internal.SessionState#executePlan- createQueryExecution 是 SessionState 的一个成员是个工厂方法创建位置如下,默认实现
org.apache.spark.sql.internal.BaseSessionStateBuilder#createQueryExecution 本质上就是new出了一个
QueryExecutiondef executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan)
- createQueryExecution 是 SessionState 的一个成员是个工厂方法创建位置如下,默认实现
然后调用
qe.assertAnalyzed方法进行分析,内容参见下节
执行计划——Analyzer
org.apache.spark.sql.execution.QueryExecution#assertAnalyzed
def assertAnalyzed(): Unit = analyzedorg.apache.spark.sql.execution.QueryExecution#assertAnalyzed
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.executeAndCheck(logical)
}sparkSession.sessionState.analyzer 的类型为 org.apache.spark.sql.catalyst.analysis.Analyzer
org.apache.spark.sql.catalyst.analysis.Analyzer#executeAndCheck
def executeAndCheck(plan: LogicalPlan): LogicalPlan = {
val analyzed = execute(plan)
try {
checkAnalysis(analyzed)
EliminateBarriers(analyzed)
} catch {
case e: AnalysisException =>
val ae = new AnalysisException(e.message, e.line, e.startPosition, Option(analyzed))
ae.setStackTrace(e.getStackTrace)
throw ae
}
}
override def execute(plan: LogicalPlan): LogicalPlan = {
AnalysisContext.reset()
try {
executeSameContext(plan)
} finally {
AnalysisContext.reset()
}
}
private def executeSameContext(plan: LogicalPlan): LogicalPlan = super.execute(plan)以上代码最终会调用 super.execute,即org.apache.spark.sql.catalyst.rules.RuleExecutor#execute
def execute(plan: TreeType): TreeType = {
var curPlan = plan
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
if (!result.fastEquals(plan)) {
queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
logTrace(
s"""
|=== Applying Rule ${rule.ruleName} ===
|${sideBySide(plan.treeString, result.treeString).mkString("\n")}
""".stripMargin)
}
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
queryExecutionMetrics.incNumExecution(rule.ruleName)
// Run the structural integrity checker against the plan after each rule.
if (!isPlanIntegral(result)) {
val message = s"After applying rule ${rule.ruleName} in batch ${batch.name}, " +
"the structural integrity of the plan is broken."
throw new TreeNodeException(result, message, null)
}
result
}
iteration += 1
if (iteration > batch.strategy.maxIterations) {
// Only log if this is a rule that is supposed to run more than once.
if (iteration != 2) {
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}"
if (Utils.isTesting) {
throw new TreeNodeException(curPlan, message, null)
} else {
logWarning(message)
}
}
continue = false
}
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
if (!batchStartPlan.fastEquals(curPlan)) {
logDebug(
s"""
|=== Result of Batch ${batch.name} ===
|${sideBySide(batchStartPlan.treeString, curPlan.treeString).mkString("\n")}
""".stripMargin)
} else {
logTrace(s"Batch ${batch.name} has no effect.")
}
}
curPlan
}以上代码核心逻辑非常简单: